pmacct를 활용한 실시간 패킷 모니터링과 BGP Null Routing 자동화
본문에 포함된 IP 주소, AS 번호, BGP Community 값은 공개용 예시값으로 변경했습니다.
실제 운영 환경에서는 ISP와 협의된 Prefix, AS 번호, Community 정책을 기준으로 적용해야 합니다.
pmacct를 활용한 실시간 패킷 모니터링과 BGP Null Routing 자동화
네트워크를 운영하다 보면 단순히 트래픽 사용량만 보는 것으로는 부족한 경우가 많습니다.
특히 DDoS 공격 대응에서는 bps 기준의 대역폭 사용량뿐만 아니라, pps(Packet Per Second) 기준의 패킷 처리량을 반드시 함께 확인해야 합니다.
이 글에서는 CentOS 서버와 Cisco Catalyst 6506-E 환경에서 운영했던 패킷 모니터링 및 자동 차단 구조를 정리합니다.
구성의 핵심은 다음과 같습니다.
- Cisco Catalyst 6506-E에서 트래픽을 미러링
- CentOS 서버에서
pmacct로 In/Out 패킷 수집 - Python 데몬으로 pmacct 집계 데이터를 읽어 MySQL에 저장
- Highcharts를 이용해 웹 페이지에서 실시간 그래프 표시
- 프로토콜별 PPS 임계치 초과 시 자동 차단
- BGP Community를 이용해 ISP 측에서 Null Routing 처리
- 차단된 호스트는 2시간 후 자동 해제
전체 구성 개요
전체 구조는 아래와 같습니다.
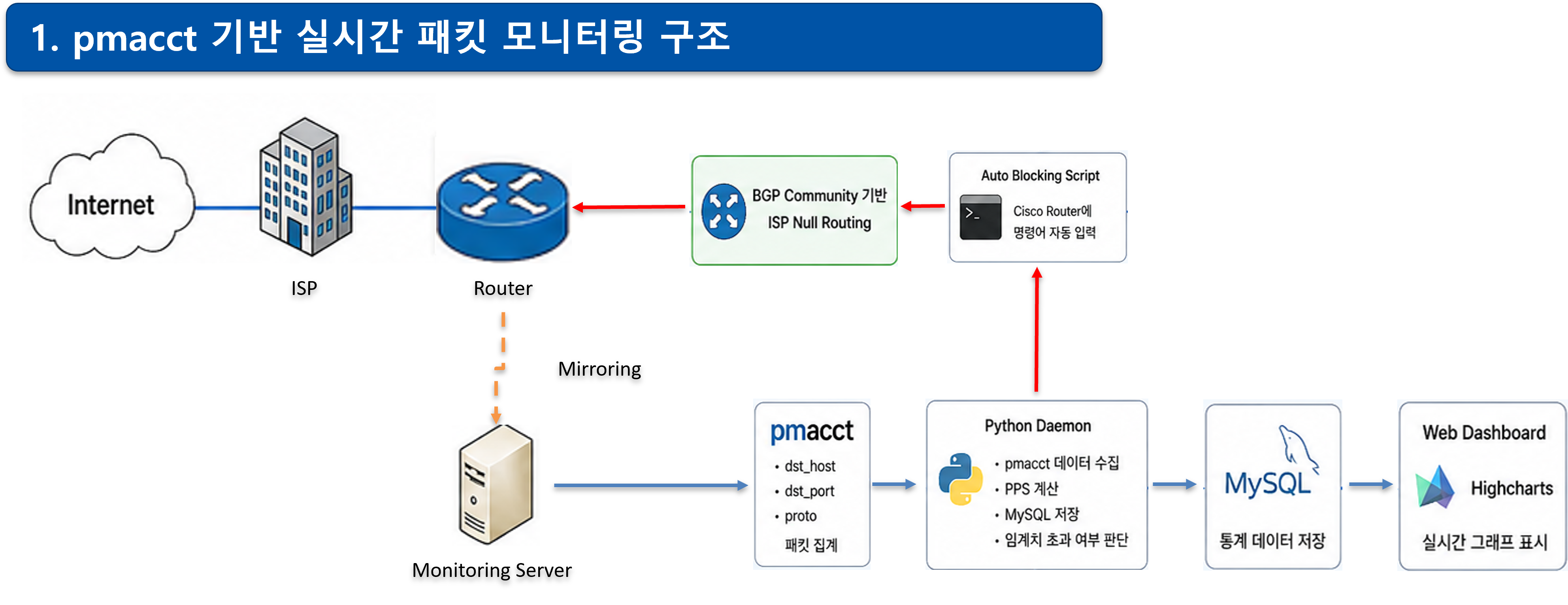
이 구성은 단순 모니터링이 아니라,
탐지 → 판단 → 차단 → 해제까지 자동화하는 것을 목표로 했습니다.
운영 환경
운영 환경은 다음과 같았습니다.
| 구분 | 내용 |
|---|---|
| OS | CentOS |
| 라우터 / 스위치 | Cisco Catalyst 6506-E |
| 패킷 수집 | pmacct |
| 데이터 처리 | Python |
| 통계 저장 | MySQL |
| 그래프 표시 | Highcharts |
| 차단 방식 | BGP Community 기반 ISP Null Routing |
| 자동 해제 | 차단 후 2시간 뒤 자동 해제 |
왜 PPS 기준 모니터링이 중요했는가
DDoS 공격이라고 하면 흔히 대역폭을 가득 채우는 대용량 공격을 먼저 떠올립니다.
하지만 실제 운영 환경에서는 대역폭보다 PPS가 더 치명적인 경우가 많았습니다.
특히 2010년대에는 L7 공격보다 L3/L4 기반 공격이 많았고,
그중에서도 짧은 패킷을 대량으로 발생시켜 장비 부하를 유발하는 공격이 위협적이었습니다.
예를 들어 다음과 같은 공격입니다.
- UDP Flood
- ICMP Flood
- TCP SYN Flood
- Fragment Flood
- Small Packet Flood
이런 공격은 패킷 크기가 작기 때문에 bps 기준으로는 크게 보이지 않을 수 있습니다.
하지만 초당 패킷 수가 급격히 증가하면 라우터, 방화벽, 로드밸런서의 처리 부하가 빠르게 올라갑니다.
즉, 대역폭 그래프만 보고 있으면 다음과 같은 상황을 놓칠 수 있습니다.
트래픽 사용량: 300Mbps
패킷 수: 800,000pps300Mbps만 보면 회선이 여유로워 보일 수 있지만,
800,000pps는 장비에 큰 부하를 줄 수 있습니다.
그래서 이 시스템에서는 bps보다 pps를 중심으로 임계치를 설정했습니다.
Cisco Catalyst 6506-E의 미러링 구성
패킷 수집 서버는 실제 서비스 경로에 직접 들어가지 않았습니다.
대신 Cisco Catalyst 6506-E에서 트래픽을 미러링하여 CentOS 서버로 전달했습니다.
이 방식의 장점은 다음과 같습니다.
- 서비스 트래픽 경로에 영향을 주지 않음
- 모니터링 서버 장애가 서비스 장애로 이어지지 않음
- 수집 서버 교체나 점검이 쉬움
- 운영 중에도 분석 정책 변경이 가능함
예시 설정 상태는 다음과 같습니다.
show monitor session all
Session 1
---------
Type : Remote Source Session
Source Ports :
Both : Te1/1
Dest RSPAN VLAN : 10
Egress SPAN Replication State:
Operational mode : Centralized
Configured mode : Centralized (default)위 설정의 의미는 다음과 같습니다.
| 항목 | 설명 |
|---|---|
| Source Ports | 미러링 대상 포트 |
| Both | 송신/수신 양방향 트래픽 복제 |
| Dest RSPAN VLAN | 미러링된 트래픽을 전달할 RSPAN VLAN |
| Centralized | 중앙 집중 방식의 SPAN 복제 모드 |
즉, Te1/1 포트를 지나는 트래픽을 복사해 RSPAN VLAN으로 전달하고,
CentOS 모니터링 서버는 해당 트래픽을 수신하여 pmacct로 분석하는 구조입니다.
pmacct를 사용한 이유
패킷 분석에는 tcpdump, nfdump, ntopng, sFlow, NetFlow 등 여러 방법이 있습니다.
그중 pmacct를 사용한 이유는 다음과 같습니다.
- pcap 기반으로 직접 패킷 수집 가능
- 원하는 필드 기준으로 유연하게 집계 가능
- memory plugin을 이용해 빠른 집계 가능
- In/Out 트래픽을 별도 설정으로 나누어 관리 가능
- 목적지 IP, 목적지 포트, 프로토콜 기준 통계 생성이 쉬움
이 시스템에서 필요한 것은 패킷 원문 저장이 아니라,
실시간으로 어느 호스트에 어떤 프로토콜의 패킷이 얼마나 들어오는지 확인하는 것이었습니다.
따라서 pmacct의 aggregate 기능이 잘 맞았습니다.
pmacct 설정 예시
아래는 In Traffic 수집용 설정 예시입니다.
IP 대역은 실제 운영 대역이 아니라 문서용 예시 대역으로 변경했습니다.
# /usr/local/pmacct/etc/total_in.conf
pcap_interface: ens1f0
daemonize: true
!plugin_buffer_size : 8192
!plugin_pipe_size : 8192000
pmacctd_force_frag_handling: true
networks_file: /usr/local/pmacct/etc/networks.def
plugins: memory[in]
aggregate[in]: dst_host, dst_port, proto
aggregate_filter[in]: dst net 198.51.100.0/24 or \
dst net 198.51.101.0/24 or \
dst net 203.0.113.0/24 or \
dst net 203.0.114.0/24
!imt_path[in]: /tmp/total_in.pipe
!imt_buckets: 65537
!imt_mem_pools_size: 1024000Out Traffic도 거의 동일한 방식으로 구성했습니다.
차이는 수집 방향과 필터 기준을 운영 환경에 맞게 조정하는 정도였습니다.
주요 설정 설명
pcap_interface
pcap_interface: ens1f0패킷을 수집할 네트워크 인터페이스입니다.
Cisco 장비에서 미러링된 트래픽이 이 인터페이스로 들어오도록 구성했습니다.
daemonize
daemonize: truepmacct를 백그라운드 데몬으로 실행합니다.
운영 환경에서는 지속적으로 패킷을 수집해야 하므로 데몬 실행이 필요합니다.
pmacctd_force_frag_handling
pmacctd_force_frag_handling: trueFragment 패킷 처리를 강제하는 옵션입니다.
DDoS 공격에서는 fragment 패킷이 섞이는 경우도 있기 때문에, 패킷 집계의 정확성을 위해 활성화했습니다.
plugins
plugins: memory[in]수집한 통계를 memory plugin에 저장합니다.
실시간 분석이 목적이었기 때문에 파일 저장보다는 메모리 기반 집계가 적합했습니다.
aggregate
aggregate[in]: dst_host, dst_port, proto이 설정이 핵심입니다.
수집한 패킷을 다음 기준으로 집계합니다.
| 필드 | 의미 |
|---|---|
| dst_host | 목적지 IP |
| dst_port | 목적지 포트 |
| proto | 프로토콜 |
즉, 다음과 같은 통계를 얻을 수 있습니다.
198.51.100.10 / UDP / 53 / 120,000pps
198.51.100.20 / TCP / 80 / 30,000pps
198.51.100.30 / ICMP / 0 / 15,000pps이렇게 보면 특정 호스트가 어떤 프로토콜로 공격받고 있는지 빠르게 파악할 수 있습니다.
aggregate_filter
aggregate_filter[in]: dst net 198.51.100.0/24 or \
dst net 198.51.101.0/24 or \
dst net 203.0.113.0/24 or \
dst net 203.0.114.0/24모든 트래픽을 수집하면 불필요한 노이즈가 많아질 수 있습니다.
따라서 보호 대상 네트워크 대역만 필터링했습니다.
실제 운영에서는 관리하는 고객 서비스 대역, 호스팅 대역, 보안 모니터링 대상 대역 등을 기준으로 설정했습니다.
Python 데몬을 이용한 통계 수집
pmacct로 집계한 데이터는 Python 스크립트에서 주기적으로 읽었습니다.
이 Python 스크립트는 단발성 실행이 아니라, 항상 백그라운드에서 동작하는 데몬 형태로 운영했습니다.
Python 데몬의 역할은 다음과 같습니다.
- pmacct 집계 데이터 읽기
- 호스트별 PPS 계산
- 프로토콜별 PPS 계산
- MySQL에 통계 저장
- 임계치 초과 여부 판단
- 차단 대상 선정
- 차단 이력 관리
- 차단 후 2시간이 지난 대상 자동 해제
구조를 단순화하면 아래와 같습니다.
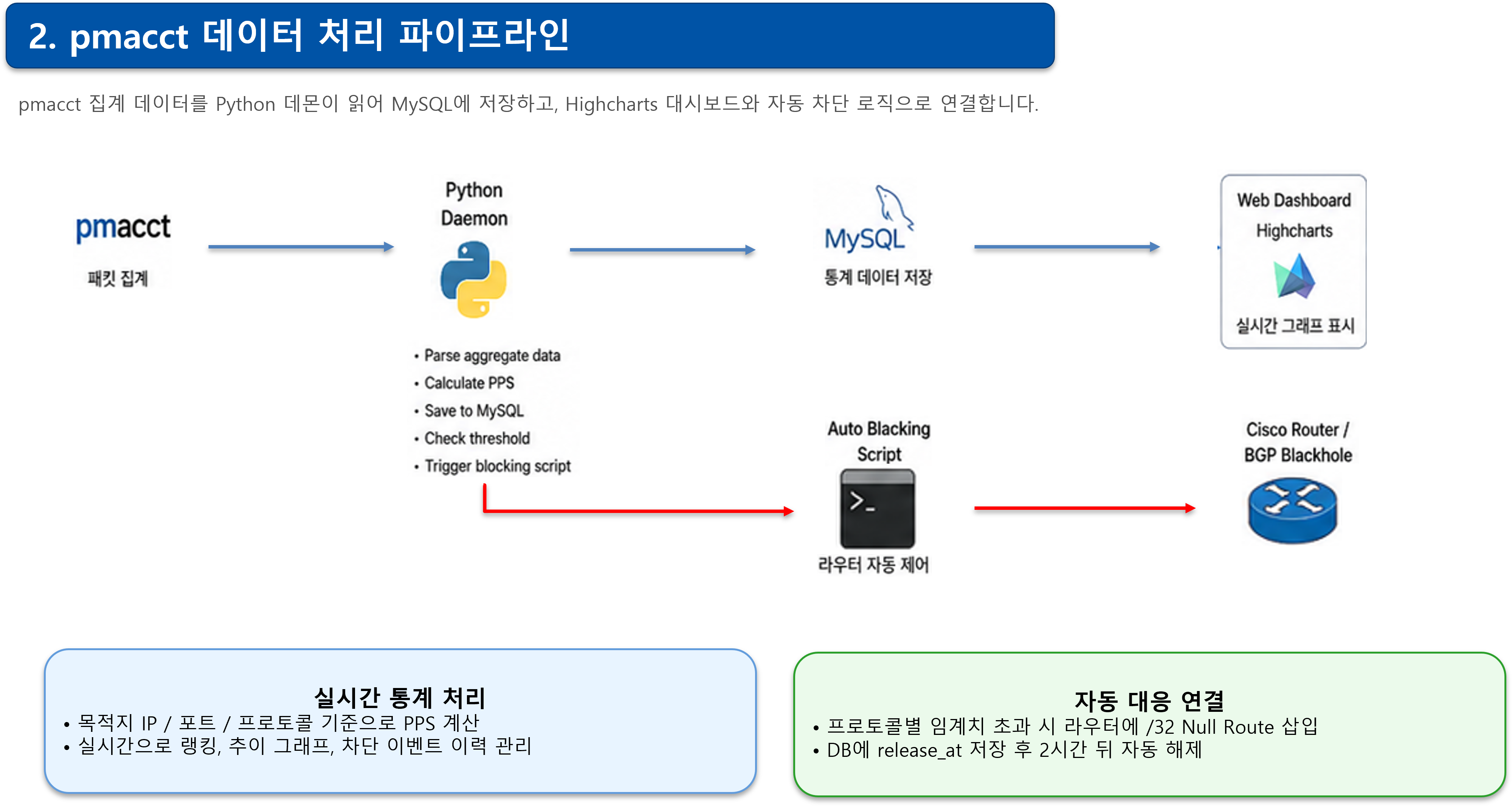
pmacct
│
▼
Python Daemon
│
├─ Parse aggregate data
├─ Calculate PPS
├─ Save to MySQL
├─ Check threshold
└─ Trigger blocking script
│
▼
Cisco Router / BGP BlackholeMySQL 테이블 구조 예시
수집 데이터는 MySQL에 저장했습니다.
아래는 이해를 돕기 위한 예시 스키마입니다.
CREATE TABLE traffic_stats (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
direction ENUM('in', 'out') NOT NULL,
host VARCHAR(45) NOT NULL,
port INT UNSIGNED NOT NULL DEFAULT 0,
proto VARCHAR(16) NOT NULL,
packets BIGINT UNSIGNED NOT NULL DEFAULT 0,
pps BIGINT UNSIGNED NOT NULL DEFAULT 0,
collected_at DATETIME NOT NULL,
PRIMARY KEY (id),
KEY idx_host_time (host, collected_at),
KEY idx_proto_time (proto, collected_at),
KEY idx_direction_time (direction, collected_at)
);차단 이력은 별도 테이블로 관리할 수 있습니다.
CREATE TABLE blackhole_events (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
target_ip VARCHAR(45) NOT NULL,
proto VARCHAR(16) NOT NULL,
detected_pps BIGINT UNSIGNED NOT NULL,
status ENUM('active', 'released') NOT NULL DEFAULT 'active',
blocked_at DATETIME NOT NULL,
release_at DATETIME NOT NULL,
released_at DATETIME NULL,
PRIMARY KEY (id),
KEY idx_target_status (target_ip, status),
KEY idx_release_at (release_at)
);이렇게 구성하면 다음과 같은 조회가 가능합니다.
SELECT host, proto, SUM(pps) AS total_pps
FROM traffic_stats
WHERE collected_at >= NOW() - INTERVAL 5 MINUTE
GROUP BY host, proto
ORDER BY total_pps DESC
LIMIT 20;Highcharts를 이용한 실시간 그래프
MySQL에 저장된 통계는 웹 페이지에서 Highcharts로 표시했습니다.
운영 화면에서는 주로 다음 항목을 확인했습니다.
- 호스트별 PPS 추이
- 프로토콜별 PPS 추이
- 포트별 트래픽 집중 현황
- In Traffic / Out Traffic 비교
- 자동 차단 이벤트 발생 이력
예시 화면 구성은 아래와 같은 형태입니다.
+----------------------------------------------------+
| Host PPS Ranking |
+-----------------+------------+----------+----------+
| Target IP | Protocol | Port | PPS |
+-----------------+------------+----------+----------+
| 198.51.100.10 | UDP | 53 | 120,000 |
| 198.51.100.20 | TCP | 80 | 35,000 |
| 198.51.100.30 | ICMP | 0 | 20,000 |
+----------------------------------------------------+
+----------------------------------------------------+
| Real-time PPS Graph |
| |
| ▲ |
| PPS │ /\ |
| │ / \ |
| │ /\ / \ |
| │_______/ \___________/ \_______ |
| |
+----------------------------------------------------+Highcharts를 사용하면 Ajax로 일정 주기마다 데이터를 가져와 실시간 그래프처럼 표시할 수 있습니다.
간단한 예시는 다음과 같습니다.
Highcharts.chart('pps-chart', {
chart: {
type: 'spline'
},
title: {
text: 'Real-time PPS by Host'
},
xAxis: {
type: 'datetime'
},
yAxis: {
title: {
text: 'Packets per Second'
}
},
series: [{
name: '198.51.100.10 UDP/53',
data: []
}]
});실제 운영에서는 TOP5 호스트와 프로토콜을 동시에 볼 수 있도록 구성했습니다.
PPS 임계치 기반 자동 차단
이 시스템의 핵심은 모니터링에서 끝나지 않고 자동 차단까지 이어지는 점입니다.
기본 흐름은 다음과 같습니다.
1. pmacct가 패킷 집계
2. Python 데몬이 집계 데이터 수집
3. 호스트별 / 프로토콜별 PPS 계산
4. 사전 정의된 임계치와 비교
5. 임계치 초과 시 차단 대상 등록
6. 라우터에 자동 명령어 입력
7. BGP Community를 이용해 ISP Null Routing 유도
8. 2시간 후 자동 해제프로토콜별 임계치는 서로 다르게 설정했습니다.
예시입니다.
THRESHOLDS = {
"TCP": 50000,
"UDP": 80000,
"ICMP": 20000,
}위 값은 설명용 예시입니다.
실제 환경에서는 회선 용량, 장비 성능, 서비스 특성, 평상시 트래픽 패턴을 기준으로 조정해야 합니다.
왜 프로토콜별로 임계치를 나누었는가
같은 PPS라도 프로토콜에 따라 의미가 다릅니다.
예를 들어 UDP는 정상 서비스에서도 순간적으로 높은 PPS가 나올 수 있습니다.
반면 TCP SYN 패킷은 비교적 낮은 PPS에서도 세션 처리 부하를 유발할 수 있습니다.
ICMP 역시 장애 분석이나 모니터링에 사용되지만, 비정상적으로 많아지면 장비에 부담을 줄 수 있습니다.
따라서 단일 임계치를 사용하는 것보다 다음과 같이 나누는 편이 현실적입니다.
| 프로토콜 | 판단 기준 |
|---|---|
| TCP | SYN 증가, 특정 포트 집중 여부 |
| UDP | 특정 포트 집중, DNS/NTP/SSDP 계열 여부 |
| ICMP | Echo Request 급증 여부 |
| Fragment | 비정상 fragment 증가 여부 |
자동 차단 스크립트 구조
자동 차단은 Python에서 pexpect를 이용해 라우터에 직접 명령어를 입력하는 방식으로 구현했습니다.
즉, 스크립트가 라우터에 접속한 뒤 프롬프트를 기다리고,
프롬프트가 나오면 다음 명령어를 보내는 방식입니다.
예시는 다음과 같습니다.
import pexpect
TIMEOUT = 5
router_ip = "192.0.2.1"
username = "router-user"
password = "router-password"
t = pexpect.spawn(f"ssh {username}@{router_ip}", timeout=TIMEOUT)
t.expect(['Username:', pexpect.EOF, pexpect.TIMEOUT], TIMEOUT)
t.sendline(username)
t.expect(['Password:', pexpect.EOF, pexpect.TIMEOUT], TIMEOUT)
t.sendline(password)
t.expect(['#', '>', pexpect.EOF, pexpect.TIMEOUT], TIMEOUT)
t.sendline('terminal length 0')
t.expect('#', TIMEOUT)운영 환경에서는 위와 같은 방식으로 로그인한 뒤,
차단 대상 IP에 대한 Null Route를 추가하거나 삭제했습니다.
로컬 Null Route와 ISP Null Routing의 차이
공격 대상 IP가 198.51.100.10이라고 가정하겠습니다.
라우터에서 아래와 같이 설정하면 해당 IP로 향하는 트래픽은 로컬 라우터에서 폐기됩니다.
ip route 198.51.100.10 255.255.255.255 Null0하지만 이 방식에는 한계가 있습니다.
트래픽이 이미 ISP를 거쳐 우리 회선까지 들어온 뒤에 버려지기 때문입니다.
[Internet]
│
▼
[ISP]
│
▼
[Our Circuit] ← 이미 대역폭 사용
│
▼
[Our Router]
│
└─ Null0에서 폐기즉, 로컬 Null Route는 장비 내부 보호에는 도움이 되지만,
회선 대역폭을 보호하는 데에는 한계가 있습니다.
그래서 공격 트래픽을 우리 회선까지 내려오기 전에 막기 위해
BGP Community 기반 ISP Null Routing을 사용했습니다.
BGP Community 기반 ISP Null Routing
BGP Community는 BGP 경로에 붙이는 태그입니다.
ISP와 미리 약속된 Community 값을 붙여 특정 Prefix를 광고하면, ISP가 해당 Prefix에 대해 특정 정책을 적용할 수 있습니다.
이 정책 중 하나가 Blackhole 또는 Null Routing입니다.
예를 들어 ISP와 다음과 같은 정책이 협의되어 있다고 가정합니다.
Community 65000:666 = Blackhole그러면 고객 라우터에서 특정 /32 Prefix를 이 Community와 함께 ISP에 광고합니다.
198.51.100.10/32 + Community 65000:666ISP는 이 경로를 수신한 뒤, 해당 목적지로 향하는 트래픽을 ISP망 내부에서 폐기합니다.
결과적으로 공격 트래픽은 우리 회선까지 내려오지 않습니다.
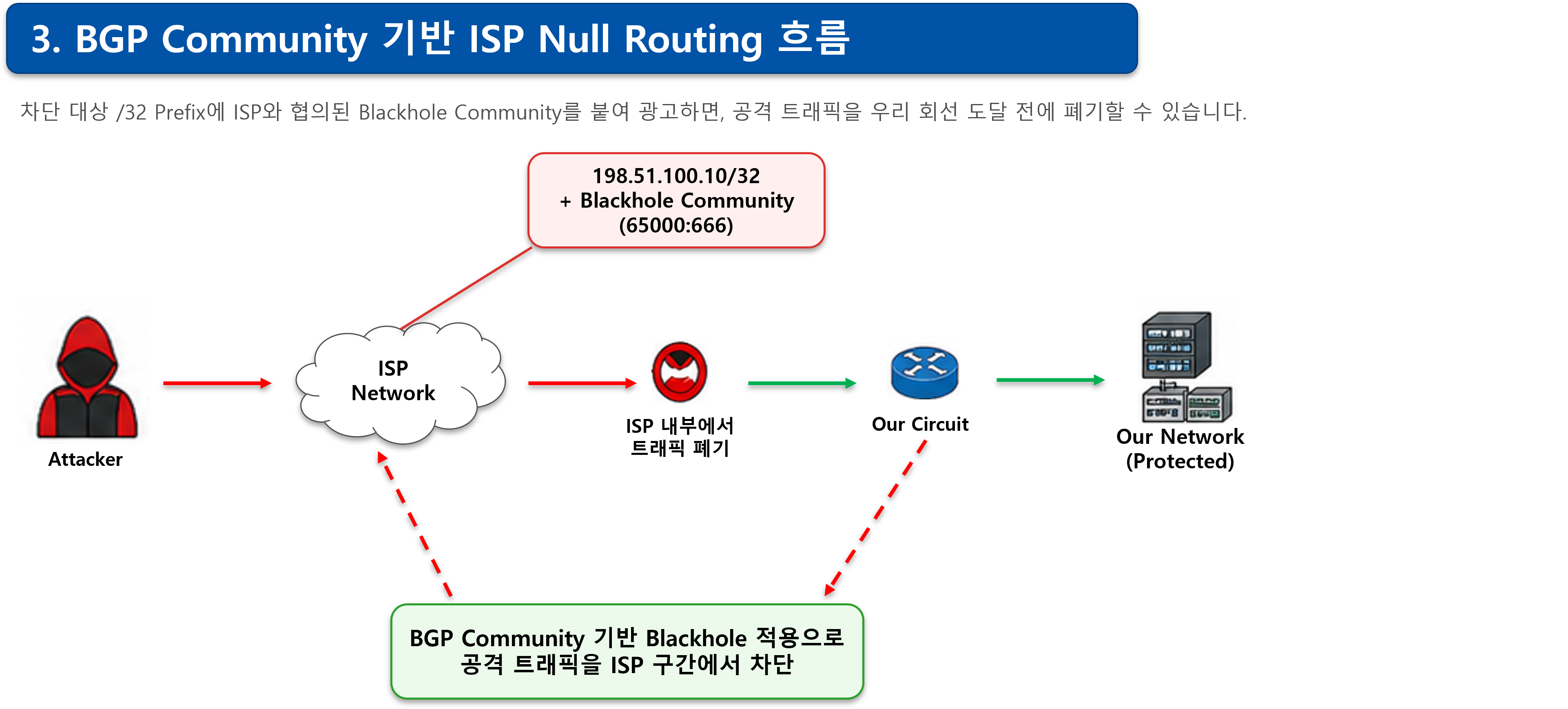
[Attacker]
│
▼
[ISP Network]
│
├─ 198.51.100.10/32 + Blackhole Community 수신
│
└─ ISP 내부에서 트래픽 폐기
│
▼
[Our Circuit]
│
└─ 공격 트래픽 유입 감소BGP Community 적용 예시
아래는 개념 설명을 위한 Cisco 설정 예시입니다.
실제 환경에서는 반드시 ISP가 제공한 Blackhole Community 값을 사용해야 합니다.
1. 차단 대상 IP에 대한 Null Route 생성
ip route 198.51.100.10 255.255.255.255 Null0 tag 666여기서 tag 666은 라우터 내부에서 route-map이 이 경로를 식별하기 위한 값입니다.
2. Static Route를 BGP로 재분배
router bgp 65000
redistribute static route-map RTBH-EXPORT정적 경로를 BGP로 광고하되, 모든 static route를 무조건 광고하면 위험합니다.
반드시 route-map으로 차단용 route만 선별해야 합니다.
3. route-map에서 tag를 매칭하고 Community 부여
route-map RTBH-EXPORT permit 10
match tag 666
set community 65000:666 additive이 설정은 다음 의미입니다.
| 명령어 | 의미 |
|---|---|
match tag 666 | tag 666이 붙은 static route만 매칭 |
set community 65000:666 additive | ISP Blackhole Community를 추가 |
additive | 기존 Community가 있으면 유지하면서 추가 |
4. BGP Neighbor에 Community 전송 허용
router bgp 65000
neighbor 203.0.113.1 remote-as 64500
neighbor 203.0.113.1 send-communitysend-community 설정이 없으면 Community가 ISP에 전달되지 않을 수 있습니다.
따라서 BGP Community 기반 정책을 사용할 때는 반드시 확인해야 합니다.
BGP Null Routing 동작 순서
실제 동작 흐름은 아래와 같습니다.
1. pmacct가 특정 호스트의 UDP PPS 급증 감지
2. Python 데몬이 임계치 초과 판단
3. 차단 대상 IP를 198.51.100.10으로 결정
4. Python 스크립트가 Cisco 라우터에 접속
5. 라우터에 /32 Null Route 추가
ip route 198.51.100.10 255.255.255.255 Null0 tag 666
6. BGP redistribute static 정책에 의해 /32 경로가 BGP로 광고됨
7. route-map에서 tag 666을 매칭
8. ISP Blackhole Community 65000:666 부여
9. ISP가 해당 Prefix를 Blackhole 처리
10. 공격 트래픽이 ISP망 내부에서 폐기됨
11. 2시간 후 Python 데몬이 Null Route 제거
12. BGP Withdraw 발생
13. ISP Blackhole 처리 해제
자동 해제 로직
차단은 2시간 후 자동 해제되도록 구성했습니다.
자동 해제가 필요한 이유는 다음과 같습니다.
- 공격이 끝났는데 계속 차단되는 상황 방지
- 수동 해제 누락 방지
- 운영자 부담 감소
- 정상 서비스 복구 시간 단축
자동 해제 흐름은 아래와 같습니다.
1. 차단 이벤트 저장
2. release_at = blocked_at + 2 hours 설정
3. Python 데몬이 주기적으로 release_at 확인
4. 시간이 지난 항목의 Null Route 제거
5. BGP Withdraw 발생
6. ISP Blackhole 해제
7. DB 상태를 released로 변경단, 공격이 계속되고 있다면 해제 후 다시 감지되어 재차단될 수 있습니다.
이 구조를 통해 자동 차단과 자동 해제가 반복적으로 동작할 수 있습니다.
운영 시 주의할 점
BGP Community 기반 Null Routing은 강력한 방법이지만, 잘못 사용하면 서비스 장애로 이어질 수 있습니다.
1. ISP와 사전 협의가 필요함
Blackhole Community 값은 ISP마다 다릅니다.
따라서 다음 항목을 반드시 확인해야 합니다.
- Blackhole Community 값
- /32 Prefix 광고 허용 여부
- 고객 보유 Prefix 범위 제한
- Community 전달 조건
- BGP 세션 정책
- max-prefix 정책
- route filtering 정책
2. send-community 설정 확인
라우터에서 Community를 설정해도 neighbor에 전달하지 않으면 의미가 없습니다.
neighbor 203.0.113.1 send-community이 설정이 빠져 있으면 ISP는 Blackhole Community를 받지 못합니다.
3. Prefix 범위 제한
일반적으로 ISP는 고객이 보유하거나 위임받은 대역 안에서만 Blackhole Prefix를 허용합니다.
예를 들어 고객 대역이 다음과 같다면:
198.51.100.0/24차단 광고는 보통 아래처럼 해당 대역 내부의 /32로 제한됩니다.
198.51.100.10/32
198.51.100.20/32외부 IP를 임의로 광고해서는 안 됩니다.
4. 오탐 방지
자동 차단 시스템에서는 오탐이 가장 위험합니다.
정상 트래픽을 공격으로 잘못 판단하면,
스스로 서비스 IP를 Blackhole 처리하는 장애가 발생할 수 있습니다.
따라서 다음 조건을 넣는 것이 좋습니다.
- 화이트리스트
- 연속 샘플 기준
- 최소 지속 시간 기준
- 특정 PPS 이상 + 특정 패킷 패턴 동시 만족
- 수동 승인 모드
- 중요 서비스 IP 자동 차단 제외
- 차단 전후 로그 저장
5. 너무 큰 Prefix 차단 금지
Blackhole은 일반적으로 단일 호스트 단위인 /32 기준으로 사용하는 것이 안전합니다.
예를 들어 아래와 같은 차단은 영향 범위가 큽니다.
198.51.100.0/24서비스 전체 대역이 차단될 수 있으므로, 자동화에서는 반드시 /32 단위로 제한하는 것이 좋습니다.
이 구성의 장점
이 구조를 운영하면서 가장 유용했던 점은 다음과 같습니다.
1. 공격 대상 호스트를 빠르게 확인할 수 있음
인터페이스 전체 트래픽만 보면 공격 대상이 보이지 않습니다.
하지만 dst_host, dst_port, proto 기준으로 집계하면 어느 호스트가 공격받는지 바로 확인할 수 있습니다.
2. PPS 기반으로 장비 부하형 공격을 탐지할 수 있음
Short packet 기반 공격은 bps 기준으로는 작아 보일 수 있습니다.
PPS 기준 모니터링을 통해 이런 공격을 더 빠르게 감지할 수 있었습니다.
3. 모니터링과 대응이 연결됨
그래프만 보는 것이 아니라, 임계치 초과 시 자동으로 차단까지 이어졌습니다.
이 때문에 야간이나 담당자가 즉시 대응하기 어려운 상황에서도 1차 방어가 가능했습니다.
4. ISP 구간에서 차단하여 회선 대역폭을 보호할 수 있음
로컬 라우터에서만 Null Route를 하면 트래픽은 이미 회선을 사용한 뒤 폐기됩니다.
반면 BGP Community 기반 ISP Null Routing은 트래픽이 우리 회선에 도달하기 전에 차단할 수 있습니다.
이 점이 가장 큰 장점이었습니다.
한계점
물론 이 방식에도 한계는 있습니다.
1. pcap 기반 수집 성능 한계
트래픽이 매우 커지면 pcap 기반 수집에서 패킷 드롭이 발생할 수 있습니다.
대규모 환경에서는 NetFlow, sFlow, 전용 DDoS 장비, Scrubbing Center와의 조합도 고려해야 합니다.
2. 차단 단위가 거칠다
Null Routing은 대상 IP 전체를 버리는 방식입니다.
따라서 특정 서비스 포트만 차단하는 세밀한 제어와는 다릅니다.
3. 자동화 안정성이 중요하다
라우터에 직접 명령어를 입력하는 구조이므로,
스크립트 오류나 로그인 실패, 프롬프트 변경 등에 대비해야 합니다.
4. L7 공격 대응에는 적합하지 않다
이 구조는 L3/L4 패킷 기반 공격 대응에는 효과적이지만,
HTTP Flood 같은 L7 공격은 별도의 WAF, CDN, Bot Management, Rate Limiting 정책이 필요합니다.
마무리
이 시스템은 단순한 패킷 모니터링 도구가 아니라,
실시간 탐지와 자동 대응을 결합한 운영 자동화 구조였습니다.
핵심은 다음과 같습니다.
Cisco SPAN/RSPAN
↓
pmacct 패킷 집계
↓
Python 데몬 분석
↓
MySQL 저장
↓
Highcharts 시각화
↓
PPS 임계치 초과 판단
↓
라우터 자동 제어
↓
BGP Community 기반 ISP Null Routing
↓
2시간 후 자동 해제지금은 Cloudflare Magic Transit, Scrubbing Center, FlowSpec, DDoS 전용 장비 등 더 발전된 선택지가 많지만,
이런 구조를 직접 운영해보면 네트워크 레벨에서 DDoS 공격이 어떻게 보이고, 어떤 방식으로 차단되는지 명확히 이해할 수 있습니다.
특히 중요한 것은 모니터링 자체가 아니라,
모니터링 결과를 실제 대응으로 연결하는 구조입니다.
패킷을 보고, 이상 징후를 판단하고, 장비를 제어하고, ISP와 연동해 상위 구간에서 차단하는 흐름은
네트워크 운영 자동화에서 매우 중요한 경험이었습니다.